

표본 크기의 계산 (Sample Size Determination)에 대해 정리해보겠습니다.
Table of Contents
표본 크기 (Sample size)
표본 크기(sample size)는 연구의 신뢰성과 통계적 유의성을 결정하는 중요한 요소입니다. 표본 크기를 적절히 설정하면 연구 결과의 정확성을 높이고, 오류를 최소화할 수 있습니다.
표본 크기 계산 (Sample size Determination)
Sample size가 너무 작으면 -> 연구 결과를 신뢰기 힘듦
Sample size가 너무 크면 -> 비용과 시간이 너무 많이 소모됨
표본이 너무 작으면 연구 결과가 신뢰할 수 없고, 표본이 너무 크면 불필요한 비용과 시간이 소모됩니다. 따라서 연구 목적과 통계적 요인을 고려하여 적절한 표본 크기를 결정해야 합니다.
정의
| 연구의 통계적 신뢰성을 확보하기 위해 필요한 최소한의 표본 수를 계산하는 과정. |
표본 크기 결정 요인
표본 크기를 결정할 때 고려해야 할 주요 요소는 다음과 같습니다.
신뢰 수준 (Confidence Level)
“우리가 얼마나 확신할 수 있을까?”
표본이 모집단을 얼마나 정확하게 대표하는지, 쉽게 말해 우리가 조사한 결과가 실제로 맞을 확률을 의미합니다.
- 보통 95%나 99% 신뢰 수준을 많이 사용합니다.
- 95% 신뢰 수준 : 100번 조사하면 각각 95번은 진짜 평균값이 포함될 가능성이 있다는 뜻이에요.
- 99% 신뢰 수준 : 100번 조사하면 각각 99번은 진짜 평균값이 포함될 가능성이 있다는 뜻이에요.
예시:
학교에서 학생들의 평균 키를 조사함. 100명의 학생을 무작위로 뽑아 평균 키를 구했더니 170cm였어요. 하지만 모든 학생을 조사한 게 아니니, 이 평균이 실제 평균과 얼마나 정확한지 확신할 수 없음
➡ 이때 “95% 신뢰 수준”을 사용하면, 표본에서 구한 신뢰 구간(예: 168cm ~ 172cm) 안에 실제 평균 키가 있을 확률이 95%라는 의미가 됩니다.
신뢰 구간 (Confidence Interval)
“실제 값이 어느 범위 안에 있을까?”
모집단 평균이 포함될 확률이 높은 범위. 쉽게 말해 조사한 값이 실제로 포함될 가능성이 있는 범위를 뜻합니다.
- 신뢰 수준이 높을수록 (예: 99% 신뢰 수준) 신뢰 구간이 더 넓어져요.
- 또, 신뢰 구간이 좁을수록 표본 크기가 커져야 합니다.
예시:
한 반에서 30명을 뽑아 평균 시험 점수를 계산했더니 85점이 나왔다고 해볼까요? 하지만 전체 학생 평균 점수는 다를 수도 있습니다.
➡ 통계를 이용해 신뢰 구간(예: 82점 ~ 88점)을 계산하면, 이 범위 안에 전체 학생의 실제 평균 점수가 포함될 확률이 95%라는 뜻이 됩니다.
➡ 만약 99% 신뢰 수준으로 하면? 범위가 80점 ~ 90점처럼 더 넓어질 것입니다.
검정력 (Statistical Power)
“내 연구가 차이를 잘 찾아낼 수 있을까?”
실제로 차이가 존재할 때 이를 발견할 확률. 신약 검사로 예를 들면, 쉽게 말해 연구에서 신약이 진짜 효과가 있을 때, 이를 발견할 확률을 뜻합니다.
- 검정력이 높으면 우리가 실제 차이를 잘 감지할 수 있어요.
- 일반적으로 80% 이상을 권장합니다.
예시:
신약이 혈압을 낮추는 효과가 있는지 실험한다고 가정해볼까요? 그런데 실험에 참여한 사람이 너무 적으면, 효과가 있어도 우연이라고 판단할 수도 있습니다.
➡ 이때 검정력이 80%면, 신약이 실제 효과가 있을 때 우리가 이를 80% 확률로 발견할 수 있다는 의미가 됩니다.
➡ 검정력을 높이려면 이런 방법들을 쓸 수 있습니다.
- 실험 방법을 정교하게 설계
- 더 많은 사람을 실험에 포함시킴
- 더 효과가 뚜렷한 약물을 사용
효과 크기 (Effect Size)
“이 차이가 얼마나 중요한가?”
변수 간 차이가 실제로 존재하는 정도. 다시 말해 효과 크기는 연구에서 발견한 차이나 변화가 얼마나 의미 있는지 나타내는 값입니다. 단순히 “차이가 있다”가 아니라, 그 차이가 실질적으로 중요한지 보는 거예요.
- 효과 크기가 작을수록 더 큰 표본이 필요합니다.
예시:
A 다이어트 약과 B 다이어트 약의 체중 감량 효과를 비교한다고 해봅시다.
- A 약: 평균 5kg 감량
- B 약: 평균 5.1kg 감량
➡ 통계적으로 “차이가 있다”고 나왔지만, 실제 차이는 0.1kg이라 효과 크기가 너무 작아요. 즉, 실제로 큰 의미는 없는 차이예요.
➡ 반대로, A 약이 5kg 감량, B 약이 10kg 감량이라면? 효과 크기가 크기 때문에 실제 차이도 중요하다고 볼 수 있어요.
표준편차 (Standard Deviation)
“데이터가 평균에서 얼마나 퍼져있을까?”
표준 편차는 데이터가 평균 주위에서 얼마나 흩어져 있는지를 나타냅니다. 값이 크면 데이터가 넓게 퍼져 있고, 값이 작으면 대부분 평균 근처에 모여 있습니다.
- 표준편차가 클수록 더 큰 표본이 필요합니다
예시:
두 반에서 학생들의 시험 점수를 비교해볼게요.
- 반 A: 점수: 80, 82, 78, 79, 81 → 평균: 80점 (표준 편차 작음 → 점수가 비슷함)
- 반 B: 점수: 60, 90, 75, 85, 80 → 평균: 80점 (표준 편차 큼 → 점수가 들쭉날쭉)
➡ 두 반의 평균 점수는 같지만, 반 B는 학생들 점수가 다양하게 퍼져 있고, 반 A는 비슷한 점수대에 몰려 있어요.
➡ 표준 편차가 크면 데이터가 다양하고, 작으면 데이터가 평균 근처에 몰려 있다는 의미예요.
유의수준 (Significance Level, α)
“우리가 틀릴 확률을 얼마나 허용할까?”
귀무가설이 참일 때 이를 기각할 확률입니다. 쉽게 설명하면 유의수준(α)은 연구에서 우리가 오류를 감수할 수 있는 최대한의 확률을 의미해요.
- 보통 5% (0.05) 를 사용하며, 이는 100번 실험하면 5번은 우연히 틀릴 수도 있다는 뜻이에요.
예시
새로운 감기약을 개발한다고 가정해볼게요.
- 귀무가설(H₀): 신약은 기존 약과 효과 차이가 없다.
- 대립가설(H₁): 신약은 기존 약보다 효과가 좋다.
실험을 했더니, 신약을 복용한 환자들이 기존 약보다 더 빨리 회복됐어요.
➡ 하지만 혹시 이 차이가 우연(운)으로 생긴 건 아닐까?
🔹 유의수준 α = 5% 라면,
“이 결과가 우연히 나올 확률이 5% 이하라면, 신약이 효과가 있다고 결론 내리겠다!” 라는 뜻이에요.
➡ 만약 p-value(유의확률)가 0.03이면?
✔ 0.03 < 0.05 → 신약이 효과가 있다는 결론을 내림 (귀무가설 기각)
➡ 만약 p-value가 0.06이면?
❌ 0.06 > 0.05 → 우연일 가능성이 5%보다 크므로 신약 효과가 있다고 결론 내릴 수 없음 (귀무가설 유지)
표본 크기 계산 공식 (Sample Size Calculation)
“우리가 원하는 정확도를 얻기 위해 몇 명을 조사해야 할까?”
표본 크기는 연구의 유형에 따라 다르게 계산됩니다. 가장 일반적인 공식은 다음과 같습니다.
| n = (Zα/2 * σ / E)² |
이 공식은 “우리가 원하는 정확도를 얻기 위해 몇 명을 조사해야 할까?” 를 결정하는 공식입니다. 연구를 할 때 너무 적은 사람을 조사하면 결과가 정확하지 않고, 너무 많은 사람을 조사하면 불필요하게 비용과 시간이 많이 들겠죠? 이 공식은 최적의 샘플 크기(표본 크기, n)를 계산하는 방법이입니다.
- n : 필요한 표본 크기 (Sample size)
- 몇 명을 조사해야 하는가?
- Zα/2: 신뢰 수준에 해당하는 Z 값
- 조사 결과가 신뢰 구간에 들어갈 확률
- (예: 95% 신뢰 수준에서 Z = 1.96)
- σ (표준편차): 모집단의 표준편차
- 데이터가 얼마나 퍼져 있는지
- 데이터가 얼마나 퍼져 있는지
- E (허용 오차) : 허용 가능한 오차의 크기
- 예시 : ±2cm, ±5점 등
예시를 한번 들어보겠습니다 🙂
예시 :성인 남자의 평균 키 계산
어떤 도시에서 성인 남성의 평균 키를 알고 싶다고 해봅시다. 하지만 모든 사람을 조사할 수는 없으니 일부만 조사해서 평균을 추정하려고 합니다.
목표:
➡ 95% 신뢰 수준으로 ±2cm 이내의 오차 범위를 가지려면 몇 명을 조사해야 할까?
주어진 정보:
- 성인 남성 키의 표준 편차(σ) = 6cm
- 신뢰 수준 95% → Zα/2=1.96Z_{\alpha/2} = 1.96Zα/2=1.96
- 허용 오차 E = 2cm
이제 공식에 대입해 볼게요.
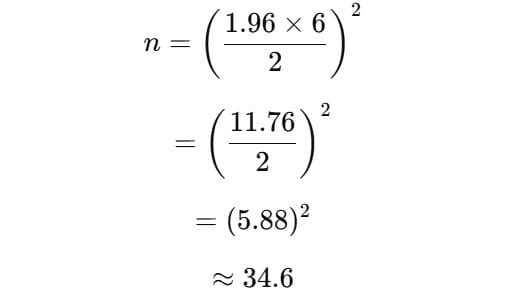
➡ 즉, 35명 이상 조사해야 원하는 정확도를 얻을 수 있다는 결론에 도달합니다.
표본 크기 예시
| 연구 유형 | 예시 |
| 설문조사 | 특정 지역의 고객 만족도를 조사하기 위해 최소 400명의 응답을 수집. |
| 임상시험 | 신약의 효과를 검증하기 위해 검정력 80%, 유의수준 5%를 설정하여 최소 200명의 환자를 모집. |
| 시장조사 | 신제품 선호도를 조사하기 위해 전국적으로 1,000명의 표본을 수집. |
정리
표본 크기 계산 (Sample size Determination) 은 연구의 신뢰성을 결정하는 핵심 과정입니다. 신뢰 수준, 검정력, 효과 크기, 유의수준 등의 요소를 고려하여 적절한 표본 크기를 설정해야 합니다. 올바른 표본 크기를 선택하면 연구 결과의 정확성을 높이고, 오류를 줄일 수 있습니다.
